Data Structures (Hash Table)
Hash Table
In computing, a hash table (hash map) is a data structure used to implement an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
Hash Table
Overview:
In general, hash table components: The idea of hashing is to distribute the entries (key/value pairs) across an array of buckets. Given a key, the algorithm computes an index that suggests where the entry can be found:
- A function to return the index: index = f(key, array_size);
- Hash function to return the transformation being done: hash = hashfunc(key);
- Creating the index: index = hash % array_size;
The end result may look something like the following:
Code:
f(key, array_size){
int hash = hash(key);
int index = hash % array_size;
return index;
}
hash(key){
// Code for whatever transformation you want
// return that transformation
}
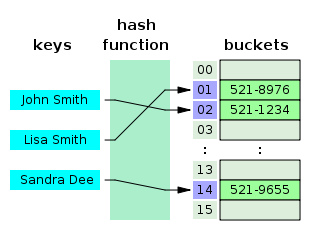
A small phone book as a hash table, notice the names/contacts are the keys then a hash function is used to transform those names into index numbers and within the "bucket/array" for the particular index contains a phone number.
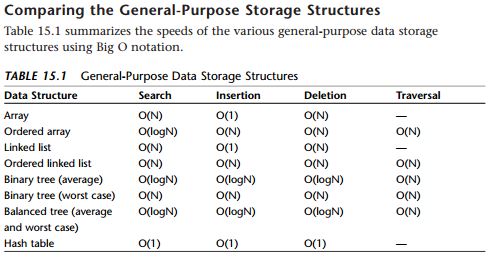
A hash table is an array coupled with a hash function which takes in a key and returns a integer hash value which maps to an index in an array. Hash tables are used when speedy insertion, deletion or lookup are a priority.
randerson112358Download PDF
Collision resolution
Hash collisions are practically unavoidable when hashing a random subset of a large set of possible keys. For example, if 2,450 keys are hashed into a million buckets, even with a perfectly uniform random distribution, according to the birthday problem there is approximately a 95% chance of at least two of the keys being hashed to the same slot. Therefore, almost all hash table implementations have some collision resolution strategy to handle such events. Some common strategies are described below. All these methods require that the keys (or pointers to them) be stored in the table, together with the associated values.
- Separate chaining
- Open addressing
- Robin Hood hashing
- Separate chaining
In the method known as separate chaining, each bucket is independent, and has some sort of list of entries with the same index. The time for hash table operations is the time to find the bucket (which is constant) plus the time for the list operation. In a good hash table, each bucket has zero or one entries, and sometimes two or three, but rarely more than that. Therefore, structures that are efficient in time and space for these cases are preferred. Structures that are efficient for a fairly large number of entries per bucket are not needed or desirable. If these cases happen often, the hashing is not working well, and this needs to be fixed.
- Open addressing
In another strategy, called open addressing, all entry records are stored in the bucket array itself. When a new entry has to be inserted, the buckets are examined, starting with the hashed-to slot and proceeding in some probe sequence, until an unoccupied slot is found. When searching for an entry, the buckets are scanned in the same sequence, until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.[13] The name "open addressing" refers to the fact that the location ("address") of the item is not determined by its hash value. (This method is also called closed hashing; it should not be confused with "open hashing" or "closed addressing" that usually mean separate chaining.)
- Robin Hood hashing
One interesting variation on double-hashing collision resolution is Robin Hood hashing.[15][16] The idea is that a new key may displace a key already inserted, if its probe count is larger than that of the key at the current position. The net effect of this is that it reduces worst case search times in the table. This is similar to ordered hash tables[17] except that the criterion for bumping a key does not depend on a direct relationship between the keys. Since both the worst case and the variation in the number of probes is reduced dramatically, an interesting variation is to probe the table starting at the expected successful probe value and then expand from that position in both directions.[18] External Robin Hashing is an extension of this algorithm where the table is stored in an external file and each table position corresponds to a fixed-sized page or bucket with B records.
Hash Table Uses:
Hash tables are the fastest data storage structure. This makes them a necessity for
situations in which a computer program, rather than a human, is interacting with
the data. Hash tables are typically used in spelling checkers and as symbol tables in
computer language compilers, where a program must check thousands of words or
symbols in a fraction of a second.
- Associative arrays
Hash tables are commonly used to implement many types of in-memory tables. They are used to implement associative arrays (arrays whose indices are arbitrary strings or other complicated objects), especially in interpreted programming languages like Perl, Ruby, Python, and PHP. - Database indexing
Hash tables may also be used as disk-based data structures and database indices (such as in dbm) although B-trees are more popular in these applications. In multi-node database systems, hash tables are commonly used to distribute rows amongst nodes, reducing network traffic for hash joins. - Caches
Hash tables can be used to implement caches, auxiliary data tables that are used to speed up the access to data that is primarily stored in slower media. In this application, hash collisions can be handled by discarding one of the two colliding entries—usually erasing the old item that is currently stored in the table and overwriting it with the new item, so every item in the table has a unique hash value. - Sets
Besides recovering the entry that has a given key, many hash table implementations can also tell whether such an entry exists or not. Those structures can therefore be used to implement a set data structure, which merely records whether a given key belongs to a specified set of keys. In this case, the structure can be simplified by eliminating all parts that have to do with the entry values. Hashing can be used to implement both static and dynamic sets.
Linear probing insertion is a strategy for resolving collisions or keys that map to the same index in a hash table. Insert the following numbers into a hash tableof size 5 using the hash function H(key) = key mod 5. Show the result when the collisions are resolved.
randerson112358Download PDF
Code:
/**
This programs uses the hash table
to change and store phone numbers from names into an array.
NOTE: If you try adding more than 1 contact this could cause collisions. For example if we had a contact named Nick and another named Norbert, using the below code, the key for both will be the first character 'N' which will map to the same number and thus inserting the second person into the phonebook/array will overwrite the first.
Written in the C programming language
By: (randerson112358)
*/
# include <stdio.h>
int main(void)
{
int phoneNumber= 5554447777;// This is the 7 digit phone number of the contact
int index;// This is the index within the phonebook/ hashTable
char[31] name = "Nick";// This is the contacts name
int table_size = 10;
int hashTable[table_size]; // This is the phone book
index = f(name[0], table_size);
hashTable[index] = phoneNumber;
system("pause"); //Comment this out if you are not using windows operating system
}
//returns the character key as an integer
int hash( char key){
return (int)key;
}
int f(char key, int hashTable_size){
int hash = hash(key);
int index = hash %hashTable_size;
return index;
}